




Diese Website verwendet Cookies, damit wir dir die bestmögliche Benutzererfahrung bieten können. Cookie-Informationen werden in deinem Browser gespeichert und führen Funktionen aus, wie das Wiedererkennen von dir, wenn du auf unsere Website zurückkehrst, und hilft unserem Team zu verstehen, welche Abschnitte der Website für dich am interessantesten und nützlichsten sind.

Kategorie:
Künstliche Intelligenz
Branche:
Gesundheitswesen
Stadt:
Oklahoma, USA
Kunde
Der Kunde ist ein US-amerikanisches Unternehmen aus dem Gesundheitswesen, das täglich große Mengen an Finanzdokumenten verarbeitet – darunter Zahlungsbestätigungen und Abrechnungen mit Versicherungen. Der Großteil der operativen Prozesse ist bereits automatisiert und basiert auf dem Austausch elektronischer Dokumente in strukturierten Formaten wie EDIFACT, was eine reibungslose Kommunikation und hohe Effizienz ermöglicht. Eine Herausforderung blieb jedoch bestehen: der Umgang mit unstrukturierten Dokumenten wie Scans, Ausdrucken oder bildbasierten Dateien, die manuell bearbeitet werden mussten – was die Skalierbarkeit einschränkte und personelle Ressourcen stark beanspruchte.
Herausforderung
Ziel war es, die Trennung und Klassifizierung mehrseitiger Papier- und Scandokumente zu automatisieren. Die Lösung musste gegen Informationsrauschen (z. B. irrelevante Seiten, gedrehte Scans, unterschiedliche Layouts) robust sein und gleichzeitig eine hohe Genauigkeit bei der Erkennung von Dokumentgrenzen und deren Zuordnung zu den richtigen Kategorien gewährleisten. Dafür war fortschrittliche Bild- und Texterkennung erforderlich – ebenso wie die Berücksichtigung kundenspezifischer interner Prozesse.

Lösung
Das Projekt wurde in mehreren Phasen umgesetzt, wobei Datenexploration, die Entwicklung von Machine-Learning-Modellen (ML) sowie auf die Geschäftsanforderungen des Kunden zugeschnittene Regeln miteinander kombiniert wurden.
Das entwickelte Lösungskonzept umfasste:
- Entwicklung von Modellen zur Erkennung von Dokumentgrenzen im Seitenstrom mittels binärer Klassifikation von Seitenpaaren – das System vergleicht benachbarte Seiten und beurteilt, ob sie demselben Dokument zugeordnet werden können. Dadurch lassen sich Seiten automatisch zu vollständigen Dokumenten gruppieren.
- Aufbau von Klassifikatoren, die Dokumente den richtigen Kategorien zuweisen – etwa Rechnungen an die Buchhaltung oder Formulare an die Abrechnungsabteilung. Dies verhindert manuelle Sortierung und reduziert Bearbeitungsverzögerungen.
- Feinabstimmung (Fine-Tuning) von Transformer-Modellen, also modernen Algorithmen, die Layout und Textinhalt ähnlich wie ein Mensch analysieren können (Dokument AI). Die Anpassung an unternehmensspezifische Daten erhöhte die Präzision deutlich.
- Entwicklung von Post-Processing-Regeln, die Ergebnisse des Modells an reale Unternehmensbedürfnisse anpassen. Beispiel: Ein Dokument ohne bestimmte Referenznummer kann zur manuellen Überprüfung markiert werden, auch wenn das Modell es korrekt erkannt hat.
Zusätzlich wurden durchgeführt:
- Explorative Datenanalyse (EDA) und Qualitätsprüfung,
- Filterung von Seiten mit Informationsrauschen,
- Entwicklung und Test von Modellen zur Trennung und Klassifikation,
- Implementierung einer Anwendung zur Integration der Modelle in bestehende Prozesse.
All diese Elemente bilden ein flexibles System, das nicht nur Dokumente erkennt und klassifiziert, sondern auch deren Weiterverarbeitung gemäß definierten Workflows unterstützt.
Ergebnisse
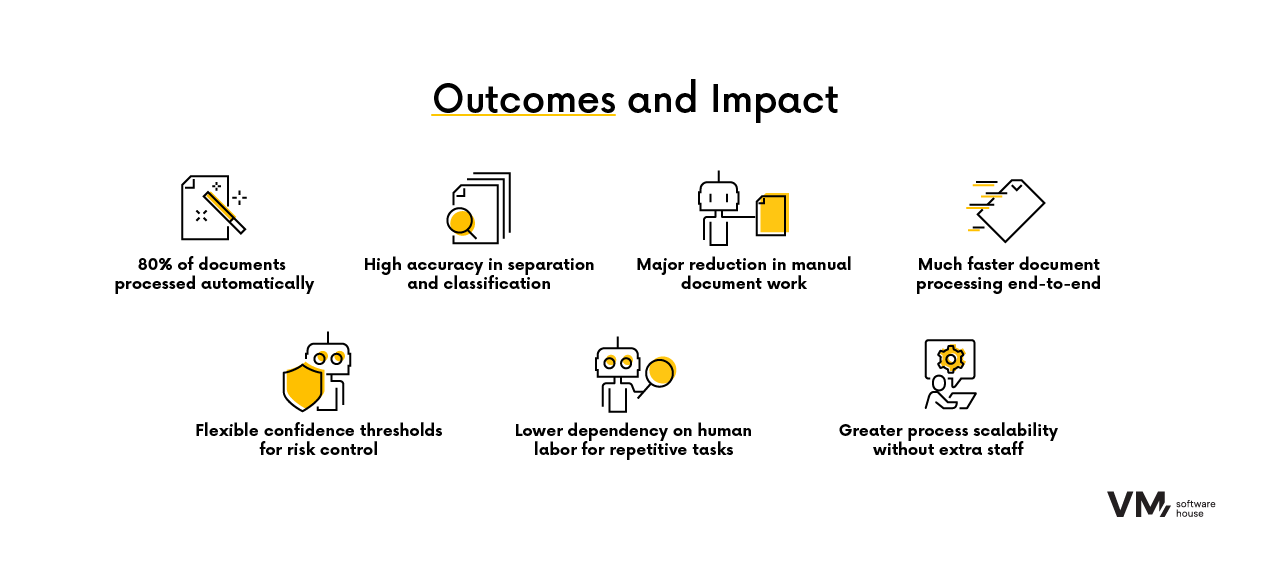
Die Einführung des Systems brachte dem Kunden messbare Verbesserungen:
- Über 80 % der Dokumente wurden ohne menschliches Zutun verarbeitet,
- Sehr hohe Genauigkeit bei Klassifikation und Dokumentgrenzenerkennung in Tests,
- Deutliche Reduzierung von Zeitaufwand und manueller Arbeit,
- Flexible Vertrauensschwellen, um das Automatisierungsniveau je nach Risiko anzupassen.
Auswirkungen auf das Geschäft:
- Höhere Skalierbarkeit ohne proportionalen Personalaufbau,
- Schnellere Dokumentenverarbeitung und reibungslosere Transaktionen,
- Geringere Abhängigkeit von manuellen, ressourcenintensiven Aufgaben.
Technologien
Die Lösung basiert auf modernsten Verfahren zur Dokumentverarbeitung und Integration multimodaler Daten:
- Einsatz von OCR, Bounding Boxes (Textpositionierung) und visuellen Scans als multimodale Eingabe,
- Aggregation von Seiten-Embeddings mit Pooling, Attention-Layern und Bi-LSTM-Netzen,
- Dokumenttrennung durch binäre Klassifikation von Seitenpaaren,
- Feinabstimmung von Transformer-Architekturen für den Gesundheitsbereich.
Die Modelle wurden vollständig auf die Prozesse des Kunden abgestimmt und ermöglichen eine Übertragbarkeit in andere Branchen wie Logistik oder öffentliche Verwaltung, in denen papierbasierte Dokumentation weiterhin eine zentrale Rolle spielt.

Design, Entwicklung, DevOps oder Cloud - welches Team brauchen Sie, um die Arbeit an Ihren Projekten zu beschleunigen?
Chatten Sie mit unseren Beratungspartnern, um herauszufinden, ob wir gut zusammenpassen.
