



 KI / ML
KI / ML  Softwareentwicklung
Softwareentwicklung 



8 popular Algorithmen des maschinellen Lernens für prädiktive Modellierung
Haben Sie sich jemals gefragt, wie Unternehmen zukünftige Trends und Verhaltensweisen genau vorhersagen können? Durch Maschinelles Lernen lässt sich Datenanalyse automatisieren. Dabei kommt es darauf an, die richtigen Algortihmen zu wenden, um sein riesieges Potenzial im Bereich der prädiktiven Modellierung zu nutzen.
Maschinelles Lernen revolutioniert die Art und Weise, wie wir in den Datenwissenschaften Daten analysieren und fundierte Entscheidungen treffen – von der Vorhersage von Aktienkursen bis hin zur Aufdeckung betrügerischer Aktivitäten.
In diesem Artikel werden wir uns auf grundlegende ML-Algorithmen konzentrieren. Wir besprechen ihre Typen, ihre Funktionsweise und die Schritte, die zum Erstellen und Trainieren Ihrer eigenen Modelle erforderlich sind.
Inhaltsverzeichnis
Was sind Algorithmen des maschinellen Lernens?
Algorithmen des maschinellen Lernens sind mathematische Modelle, die auf Daten trainiert werden. Sie nutzen statistische und prädiktive Analysetechniken bei der Datenanalyse, um Muster und Beziehungen zwischen Daten zu erkennen. Anschließend nutzen sie dieses Wissen, um Vorhersagen zu treffen oder neue, ungeprüfte Daten zu verarbeiten.
Ihr Hauptvorteil ist die Fähigkeit, Trainingsdaten allgemein in neuen, bisher unbekannten Formen zu verarbeiten, so dass sie in realen Szenarien genaue Vorhersagen machen können.
Kriterien für die Auswahl eines Algorithmus
Welcher Algorithmus zu wählen ist, hängt von vielen Variablen ab. Selbst die erfahrensten Datenwissenschaftler können den besten Algorithmus nicht bestimmen, bevor sie ihn an einem bestimmten Datensatz getestet haben.
Daher ist die Wahl weitgehend Spekulation, ohne dass zuvor mehrere Algorithmen an einem bestimmten Datensatz getestet wurden. Es gibt jedoch eine Reihe von Regeln, die Ihnen auf der Grundlage mehrerer Variablen helfen, Ihre Suche auf 2-3 Algorithmen einzugrenzen, die für Ihren speziellen Fall am besten geeignet sind. Sie können die angegebenen Algorithmen an einem realen Datensatz testen, so dass die richtige Entscheidung dann nur noch eine Formsache ist.
1. Art der Aufgabe
In der Regel passen wir die Methoden an, indem wir mit den einfachsten beginnen, um herauszufinden, ob es sinnvoll ist, tiefgreifendere und komplexere Algorithmen zu verwenden. Zunächst analysieren wir, an welcher Art von Aufgabe wir arbeiten; handelt es sich beispielsweise um eine Klassifizierungsaufgabe, bei der wir bestimmte Kategorien vorhersagen wollen? Oder handelt es sich um eine Regressionsaufgabe, bei der kontinuierliche Werte vorhergesagt werden sollen? Je besser wir die Art der Aufgabe verstehen, desto genauer wird die Wahl eines bestimmten Algorithmus ausfallen.
2. Umfang und Art der Daten
Das Verstehen der Daten ist der Schlüssel zum Erfolg. Deshalb analysieren wir immer die spezifischen Daten, mit denen wir zu tun haben; die richtigen Daten liefern die Informationen, die wir brauchen. Die explorative Datenanalyse ist immer der erste Schritt in einem Projekt.
Das Verständnis der Daten ist auch in den Zwischenstadien hilfreich:
-Bevor wir zur Datenbereinigung übergehen, sammeln wir Informationen über fehlende Werte.
– Bevor wir mit der Umwandlung der Daten beginnen, müssen wir wissen, welche Art von Variablen in der Menge enthalten sind.
– Bevor wir mit der Modellierung beginnen, prüfen wir, ob sich Ausreißerbeobachtungen und Variablen mit ungewöhnlichen Verteilungen im Datensatz befinden.

Einige Algorithmen sind besser für kleine Datensätze geeignet, während andere effektiv mit großen Datensätzen und komplexen Beziehungen zwischen Variablen umgehen können.
Bei einem kleinen Datensatz mit einer einfachen Beziehung zwischen den Variablen können Algorithmen wie die lineare Regression oder die logistische Regression ausreichend sein. Bei einem umfangreichen Datensatz mit komplexen Beziehungen sind Algorithmen wie Random Forests oder Support Vector Machines möglicherweise besser geeignet.
3. Interpretation vs. Leistung
Ein weiterer zu berücksichtigender Faktor ist der Kompromiss zwischen Interpretierbarkeit und Effizienz. Einige Algorithmen, wie z. B. Entscheidungsbäume, lassen eine Interpretation zu und liefern klare Erklärungen für ihre Vorhersagen. Andere Algorithmen, wie z. B. neuronale Netze, erbringen zwar bessere Leistungen, sind aber nicht interpretierbar.
Wenn die Interpretierbarkeit für Ihr Projekt entscheidend ist, sind Algorithmen wie Entscheidungsbäume oder logistische Regression eine gute Wahl. Wenn die Leistung das Hauptziel ist und die Interpretierbarkeit keine Priorität hat, sind neuronale Netze oder Deep-Learning-Modelle möglicherweise besser geeignet.
4. Die Komplexität des Algorithmus
Auch die Komplexität des Algorithmus ist ein wesentlicher Faktor. Einige Algorithmen sind relativ einfach und leicht zu implementieren, während andere komplexer sind und fortgeschrittene Programmierkenntnisse oder Rechenressourcen erfordern.
Wenn Sie nur über begrenzte Programmierkenntnisse verfügen, sind Algorithmen wie lineare Regressionen oder Entscheidungsbäume ein guter Ausgangspunkt. Wenn Sie über fortgeschrittenere Programmierkenntnisse und Computerressourcen verfügen, können Sie komplexere Algorithmen wie neuronale Netze oder DL-Modelle erforschen.
Anhand dieser Faktoren können Sie Ihre Optionen eingrenzen und den geeigneten Machine-Learning-Algorithmus für Ihr Projekt auswählen. Es ist wichtig, mit verschiedenen Algorithmen zu experimentieren und ihre Leistung für Ihre spezifische Aufgabe und Ihre Daten zu bewerten.
Einteilung der Algorithmen für maschinelles Lernen
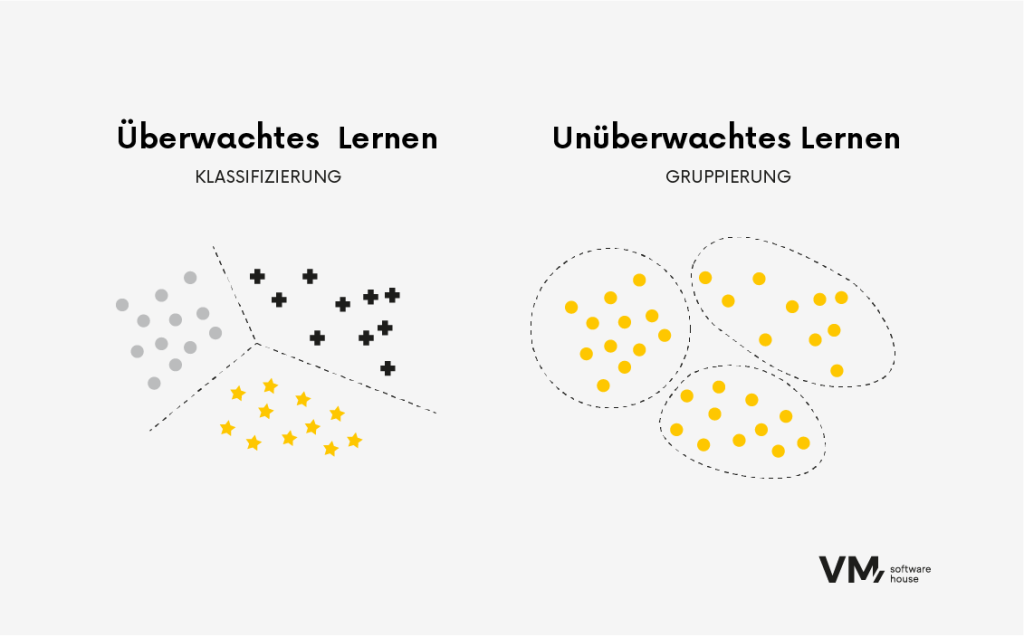
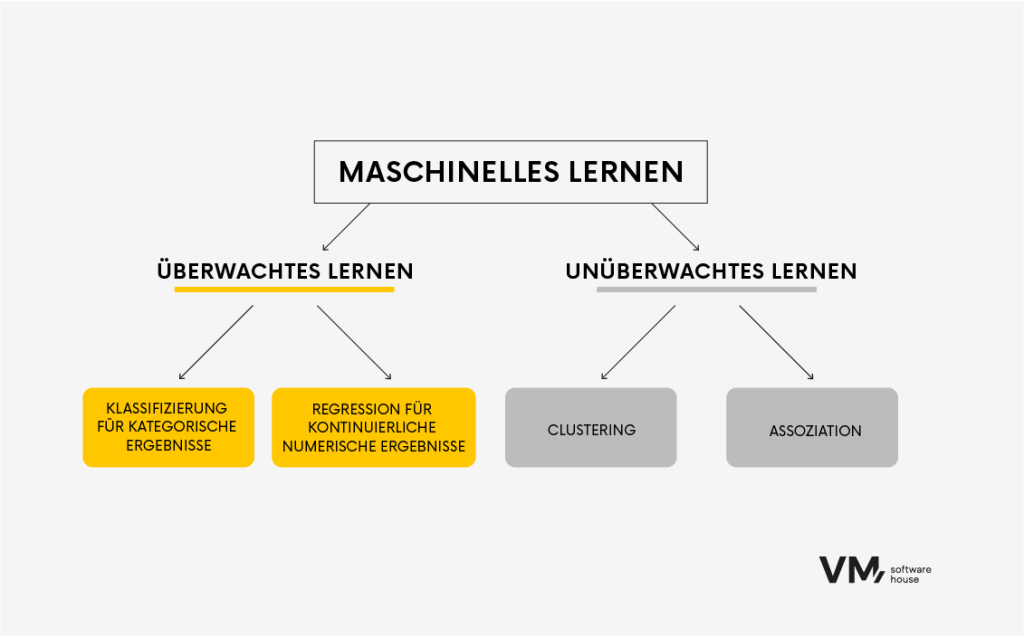
Die allgemeinste Art, die Algorithmen zu unterteilen, basiert auf der Art des Lernens: überwachtes und unüberwachtes Lernen.
Überwachtes Lernen
Algorithmen des überwachten Lernens werden auf markierten Daten trainiert, wobei die Eingabedaten mit der richtigen Ausgabe- oder Zielvariablen verknüpft werden. Der Algorithmus lernt, Eingabedaten den richtigen Ausgabedaten zuzuordnen, indem er Muster und Beziehungen in den Daten findet. Diese Art von Algorithmus wird üblicherweise für Aufgaben wie Klassifizierung und Regression verwendet.
Wir verwenden Algorithmen für maschinelles Lernen , z.B. Regression, um einen numerischen Wert auf der Grundlage von Ausgangsmerkmalen vorherzusagen. Dieser Wert könnte beispielsweise die geschätzte Kreditwürdigkeit, das Betrugsrisiko für eine bestimmte Transaktion oder ein binärer Wert sein, der angibt, ob ein bestimmter Bankkunde ein guter oder schlechter Kreditnehmer ist. Zusammenfassend lässt sich sagen, dass wir in diesem Fall genau wissen, wonach wir suchen und worauf wir unsere Entscheidungen stützen werden.
Ein Beispiel wäre ein Datensatz von Bankkunden, der durch Variablen wie Geburtsdatum, Ausweisnummer, Kontostand, Wohnanschrift, Kreditdaten, Transaktionshistorie usw. beschrieben wird.
Unüberwachtes Lernen
Algorithmen des unüberwachten Lernens werden auf unmarkierten Daten trainiert, bei denen nur Eingabedaten ohne eine entsprechende Ausgabe- oder Zielmarkierung verfügbar sind. Das Ziel des unüberwachten Lernens ist es, versteckte Muster oder Strukturen in den Daten zu entdecken. Unüberwachte Lernalgorithmen sind von Vorteil, wenn die zugrunde liegende Struktur der Daten unbekannt ist.
Wir verwenden Algorithmen dieser Art häufig bei Aufgaben wie Clustering und Dimensionalitätsreduktion. Beispielsweise gruppiert der Algorithmus ähnliche Datenpunkte bei Clustering-Aufgaben auf der Grundlage ihrer internen Ähnlichkeiten. Dies kann bei Aufgaben wie der Kundensegmentierung nützlich sein, wo der Algorithmus Gruppen von Kunden mit ähnlichen Vorlieben oder Verhaltensweisen identifizieren kann.
Beliebte Algorithmen für maschinelles Lernen
Algorithmen für maschinelles Lernen gibt es in vielen Formen und Formaten, die jeweils einzigartige Merkmale aufweisen. In diesem Abschnitt werden wir einige beliebte Algorithmen und ihre Anwendungen in verschiedenen Branchen erörtern.
1. Binäre Klassifizierung
Bei Klassifizierungsaufgaben lernt der Algorithmus, die Eingabedaten in zwei vordefinierte Kategorien oder Klassen einzuordnen.
Die Klassifizierung wird in Situationen wie der Objekterkennung, allen Arten der Automatisierung, der Zählung von Objekten, aber auch in medizinischen Fragen wie der Erkennung verschiedener Veränderungen in der medizinischen Bildgebung verwendet, zum Beispiel, wenn wir zwischen einer kranken und einer gesunden Person unterscheiden wollen.
Bei der binären Klassifizierung wird ein Algorithmus trainiert, um Eingabedaten zwei vorgegebenen Kategorien oder Klassen zuzuordnen. So kann beispielsweise ein Algorithmus für überwachtes Lernen darauf trainiert werden, durch Analyse eines markierten E-Mail-Datensatzes festzustellen, ob eine E-Mail Spam ist oder nicht. Die binäre Klassifizierung wird häufig verwendet, weil wir einen gegebenen Datensatz durchsieben und zwei Gruppen trennen müssen.
Welche Fragen beantworten die Klassifizierungsalgorithmen? Zum Beispiel:
- Wird der Kunde ein guter Kreditnehmer sein? (wird den Kredit vollständig und ohne wesentliche Verzögerungen zurückzahlen) | 0,1 (ja oder nein)
- Wird ein bestimmter Kunde unsere Dienste kündigen wollen? | 0,1 (ja oder nein)
- Ist die Transaktion betrügerisch? | 0,1 (ja oder nein)
2. Mehrklassen-Klassifizierung
Von einer Mehrklassen-Klassifikation spricht man, wenn man versucht, ein einziges Ergebnis vorherzusagen, wie es bei der binären Klassifikation der Fall ist, aber mit mehr als zwei Klassen. Manchmal wollen wir etwas Komplizierteres unterscheiden. Bei der Unterscheidung von Krankheiten wollen wir zum Beispiel wissen, um welche Krebsart es sich handelt oder in welchem Stadium er sich befindet.

In der obigen Abbildung sehen wir die Anwendung von Algorithmen unter Aufsicht. Die verwendeten Methoden sind:
- KLASSIFIZIERUNG – mit Hilfe der Klassifizierung können wir sagen, dass auf dem Bild ein Hund, ein Plüschtier und eine Tasse zu sehen sind.
- OBJEKTENTDECKUNG – wir wollen einen Hund in einem bestimmten Becher finden. Mit dieser Methode werden wir die Grenzen des Objekts (Rechteck) und die Wahrscheinlichkeit, dass sich dieses bestimmte Objekt im Bild befindet, bestimmen.
- SEGMENTIERUNG – eine Methode, bei der versucht wird, einzelne Objekte zu finden und sie dann so genau wie möglich zu markieren und voneinander zu trennen,
- SEMANTISCHE SEGMENTIERUNG – eine Methode, die ein Objekt mit Objekten desselben Typs markiert.
3. Lineare Regression
Die lineare Regression ist eine lineare Gleichung, die die Beziehung zwischen verschiedenen Dimensionen bestimmt. Der Algorithmus lernt, die am besten passende Linie zu finden, die die Summe der quadratischen Fehler zwischen vorhergesagten und tatsächlichen Werten minimiert. Er wird häufig bei numerischen Vorhersagen verwendet. Ein Beispiel hierfür ist ein Algorithmus, der den Wert eines Hauses anhand von Merkmalen wie Lage, Anzahl der Schlafzimmer und Fläche vorhersagen kann.
Die lineare Regression wird in den Finanz-, Wirtschafts- und Sozialwissenschaften häufig verwendet, um die Beziehungen zwischen Variablen zu analysieren und Vorhersagen zu treffen. Sie kann zum Beispiel zur Vorhersage von Aktienkursen auf der Grundlage historischer Daten verwendet werden.
4. Logistische Regression
Die logistische Regression ist ein beliebter Algorithmus zur Vorhersage eines binären Ergebnisses, z. B. „ja” oder „nein”, auf der Grundlage früherer Datensatzbeobachtungen.
Bestimmt die Beziehung zwischen einer binären abhängigen Variablen und einer oder mehreren unabhängigen Variablen durch Anpassung einer logistischen Funktion an die Daten. Der Algorithmus lernt, die am besten passende Kurve zu finden, die zwei Klassen voneinander trennt.
Logistische Regressionen werden für prädiktive Modellierungen im Marketing, im Gesundheitswesen und in den Sozialwissenschaften häufig eingesetzt, um die Abwanderung von Kunden vorherzusagen, Betrug aufzudecken und Krankheiten zu diagnostizieren. Sie kann beispielsweise dazu verwendet werden, um festzustellen, ob ein Kunde aufgrund seines bisherigen Verhaltens wahrscheinlich einen Kauf abbricht, oder um anhand seiner Symptome und seiner Krankengeschichte zu diagnostizieren, ob ein Patient eine bestimmte Krankheit hat.
5. Entscheidungsbäume
Entscheidungsbäume sind vielseitige Algorithmen, die sowohl für Klassifizierungs- als auch für Regressionsaufgaben verwendet werden können. Sie unterteilen die Daten auf der Grundlage der eingegebenen Merkmalswerte in Teilmengen und treffen Vorhersagen, indem sie den Baum von der Wurzel bis zum Blattknoten durchlaufen. Der Vorteil von Bäumen ist die Interpretierbarkeit der Vorhersageergebnisse.
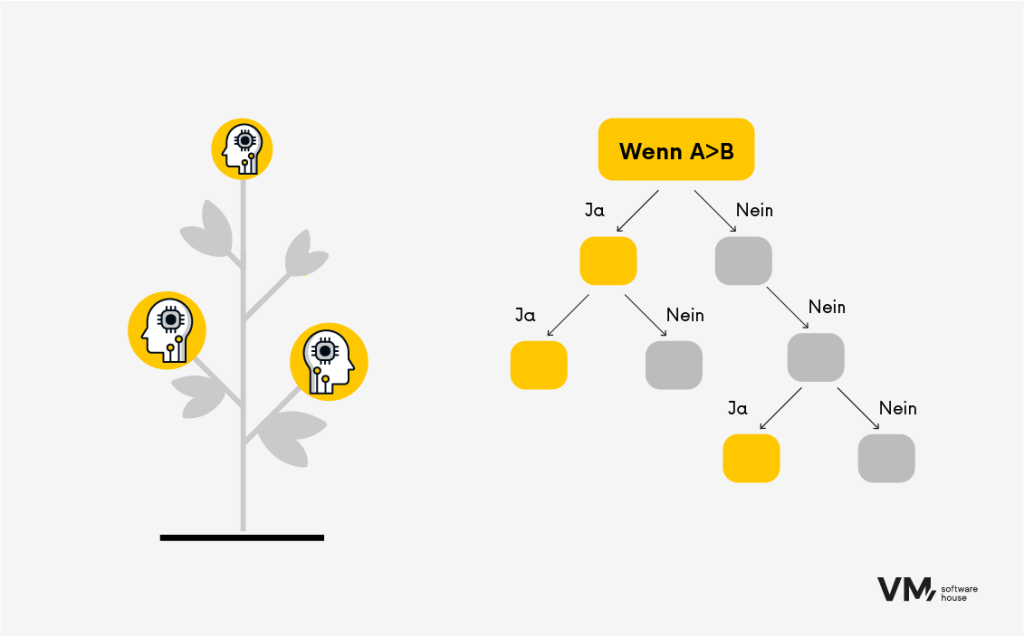
Beispiel:
Sie haben die Testergebnisse. Sie möchten mehr erfahren:
- Geschlechtertrennung: weiblich oder männlich? Sind Sie eine Frau? Gehen Sie zum folgenden Abschnitt.
- Einteilung nach Alter. Unterteilen Sie z. B. in fünf verschiedene Altersgruppen:
- 0-18 Jahre alt
- 18-25 Jahre alt
- 25-40 Jahre alt
- 40-55 Jahre alt
- 55-65 Jahre alt
3. Einteilung nach Merkmalen des Testergebnisses (Bestimmung der Stufe eines bestimmten Ergebnisses). Der Algorithmus führt Sie Schritt für Schritt bis zur letzten Stufe, nach der das Endergebnis ermittelt und entsprechend benannt wird.
Entscheidungsbäume lernen relativ schnell und benötigen nicht viel Rechenleistung. Damit ein Algorithmus jedoch weiß, wie er diesen Baum automatisch aufbauen kann und in der Lage ist, die entsprechenden Ebenen zu „durchforsten”, benötigt er eine ausreichend große Datenmenge, damit etwaige Fehler so gering wie möglich ausfallen.
Diese Algorithmen werden für die prädiktive Modellierung in den Bereichen Finanzen, Marketing und E-Commerce häufig zur Bonitätsbewertung, Kundensegmentierung und für Produktempfehlungen eingesetzt. So kann ein Entscheidungsbaum beispielsweise vorhersagen, ob ein Kunde aufgrund seines Einkommens, seines Alters und seiner Kredithistorie kreditwürdig ist, oder dem Kunden Produkte auf der Grundlage seiner früheren Einkäufe empfehlen.
6. Verstärkter Entscheidungsbaum
Dieser Algorithmus wird sowohl für Klassifizierungs- als auch für Regressionsaufgaben verwendet. Er nutzt das Konzept des Ensemble-Lernens, bei dem mehrere schwache Lernalgorithmen (z. B. flache Entscheidungsbäume mit nur wenigen Ebenen) kombiniert werden, um eine genauere Vorhersage zu erstellen. Die progressive Verstärkung ermöglicht den sequenziellen Aufbau von Vorhersagemodellen, wobei jeder Baum darauf abzielt, den vom vorherigen Baum hinterlassenen Fehler vorherzusagen; so entsteht eine Folge von Bäumen. Das Ergebnis ist ein sehr genauer Algorithmus, der jedoch viel Speicherplatz benötigt.
Boosted Decision Tree wird z. B. im Investmentbanking oder bei der Kreditrisikobewertung eingesetzt, d. h. überall dort, wo es auf Genauigkeit ankommt, wo es keine begrenzten Ressourcen gibt oder wo der Algorithmus nicht häufig aktualisiert werden muss.
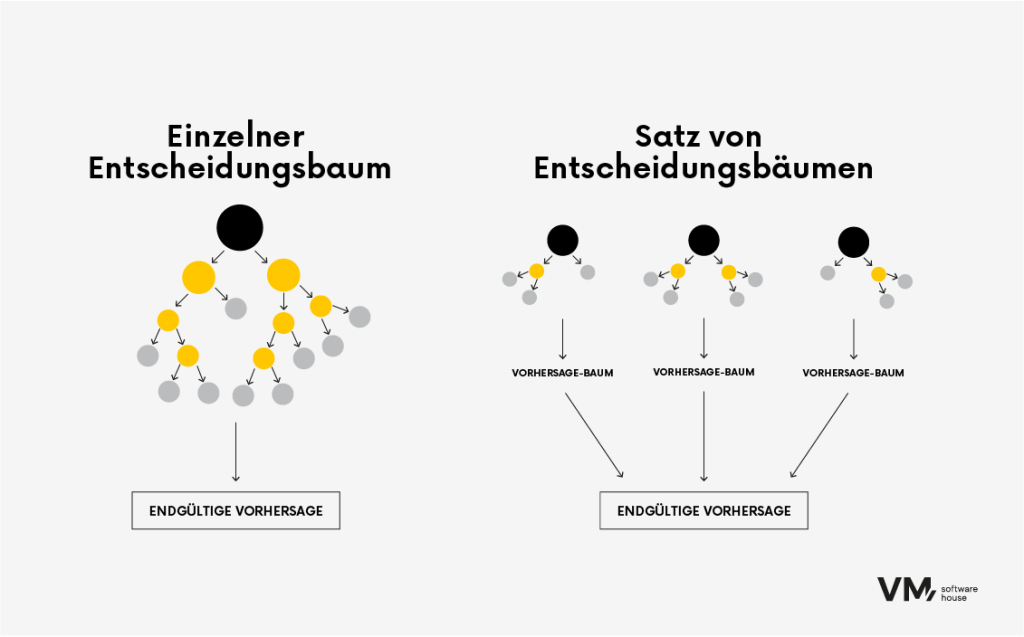
7. Zufälliger Wald
Der Random-Forest-Algorithmus ist ein beliebtes maschinelles Lernverfahren, das für Klassifizierungs- und Regressionsaufgaben eingesetzt wird. Er gehört zu den Ensemble-Lernmethoden, bei denen während des Trainings mehrere Entscheidungsbäume gebildet und kombiniert werden, um eine genauere und stabilere Vorhersage zu treffen.
Es ist, als würde eine Gruppe verschiedener Experten zusammenarbeiten, um eine Entscheidung zu treffen. Jedes Modell trägt seine Erkenntnisse bei, und zusammen erzielen sie eine bessere Leistung als jedes einzelne Modell. Der Hauptvorteil von Random Forests besteht darin, dass das Modell genauer ist als ein Entscheidungsbaum, denn je vielfältiger die Informationsquellen sind, desto robuster ist ein Random Forest, da eine einzelne anomale Datenquelle ihn nicht beeinflussen kann.
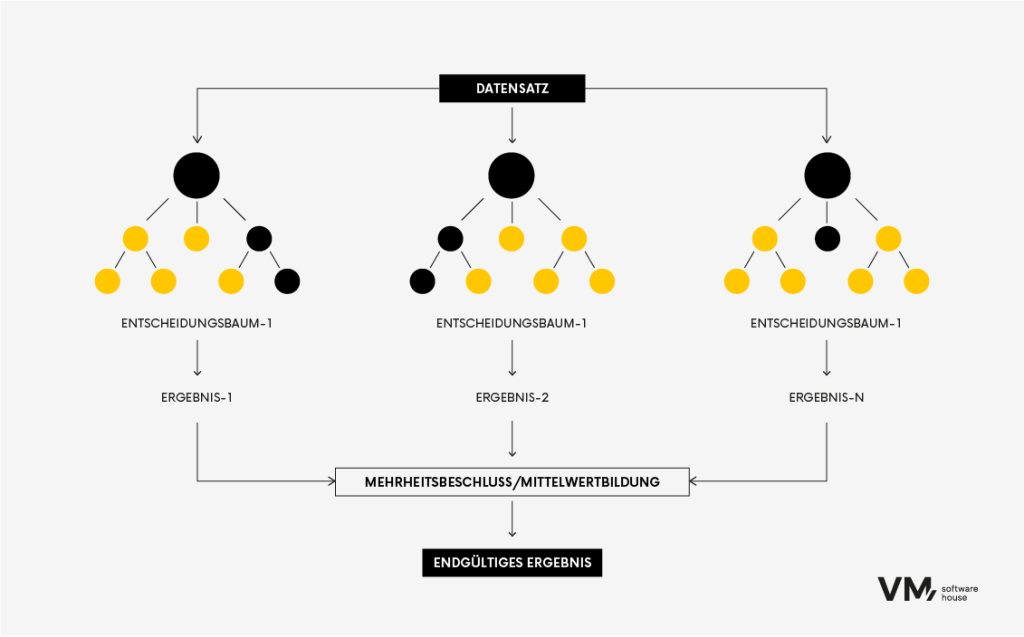
Der Nachteil dieser Methode besteht darin, dass sie große Datenmengen erfordert, was sie rechenintensiv macht. Sie wird am häufigsten für prädiktive Modellierungen Investmentbanking oder in Systemen zur Bewertung des Kreditrisikos eingesetzt.
8. Neuronale Netze
Dies ist einer der komplexeren Algorithmen, die wir in diesem Artikel vorstellen. Er ist von der Funktionsweise des menschlichen Gehirns inspiriert und ahmt die Prozesse nach, mit denen biologische Neuronen zusammenarbeiten, um Phänomene zu erkennen, Optionen abzuwägen und Schlussfolgerungen zu ziehen.
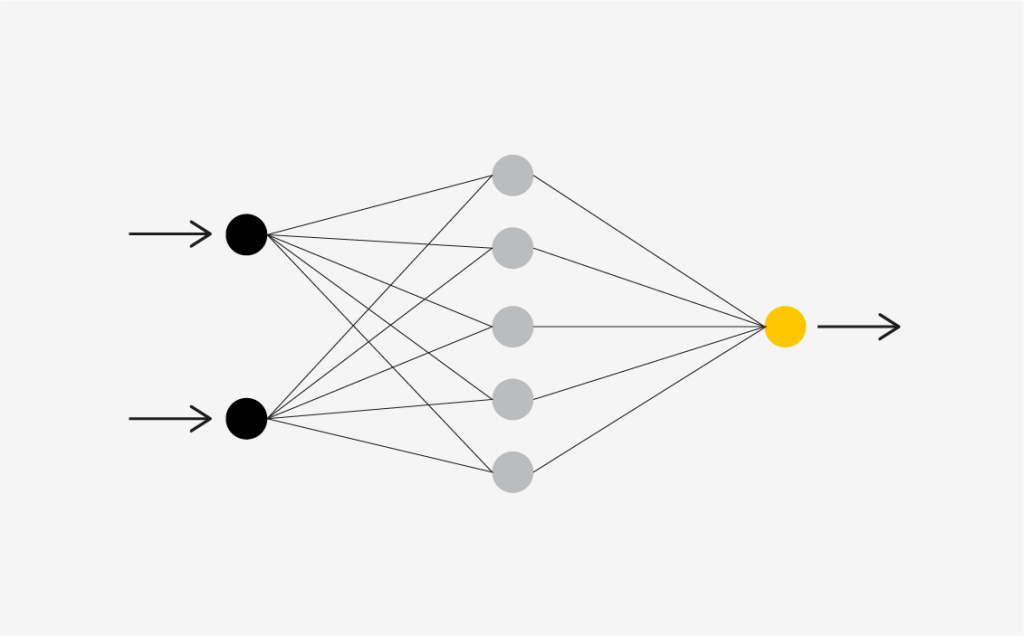
Neuronale Netze werden aus künstlichen Neuronen, so genannten Einheiten, aufgebaut. Diese Einheiten arbeiten zusammen, um wie das menschliche Gehirn zu lernen, Muster zu erkennen und Entscheidungen zu treffen. Die Funktionsweise neuronaler Netze ist vergleichbar mit der Kombination der Leistung eines Computers mit dicht verbundenen Gehirnzellen.
Arbeitsweise
Computer verwenden Transistoren – kleine Schaltgeräte. Moderne Mikroprozessoren enthalten über 50 Milliarden Transistoren, sind aber in relativ einfachen seriellen Ketten verbunden. Die Transistoren sind in Grundschaltungen verbunden, die als Logikgatter bekannt sind. Neuronale Netze ahmen die Verbindungen echter Neuronen nach, indem sie künstliche Neuronen (Einheiten) in Schichten verbinden.
Diese Methode wird am häufigsten für komplexe Probleme mit großen Datensätzen verwendet, bei denen es schwierig ist, einfache Muster zu erkennen. Ihr Hauptvorteil ist, dass sie komplexe Muster lernen kann und für Deep-Learning-Aufgaben geeignet ist. Auf der anderen Seite erfordert der Nachteil erhebliche Rechenressourcen (GPU) und umfangreiche Trainingsdaten.
Neuronale Netze werden in verschiedenen Bereichen eingesetzt:
- Bilderkennung: Identifizieren und Finden von Objekten in Bildern.
- Verarbeitung natürlicher Sprache: Verstehen und Erzeugen menschlicher Sprache.
- Empfehlungssysteme: Personalisierte Vorschläge (z. B. Netflix-Empfehlungen).
- Medizinische Diagnostik: Erkennung von Krankheiten anhand medizinischer Bilder.
- Finanzielle Prognosen: Börsentrends, Bewertung des Kreditrisikos usw.
Die Zukunft der prädiktiven Analytik im maschinellen Lernens
Predictive Analytics-Modelle spielen im Bereich der Prognosen eine wichtige Rolle, denn durch die Analyse großer Mengen historischer Daten können Unternehmen zukünftige Leistungen mit einem hohen Maß an Genauigkeit vorhersagen.
Sie bilden auch die Grundlage für die strategische Entscheidungsfindung und die betriebliche Optimierung in verschiedenen Branchen. Ganz gleich, ob es um die Rationalisierung von Hygieneinspektionen in Restaurants, die Lösung komplexer geschäftlicher Herausforderungen oder die Anpassung von Marketingstrategien geht: Die Fähigkeit, künftige Leistungen vorherzusagen, stellt einen großen Fortschritt in der Art und Weise dar, wie Daten Fortschritt und Innovation vorantreiben.
Fragen Sie sich, wie künstliche Intelligenz die Datenanalyse und die Möglichkeiten der Risikobewertung revolutioniert? Lesen Sie mehr zu diesem Artikel: Daten- und Risikoanalyse – wie KI Ihre Prozesse verbessern wird
Durch den Einsatz von Algorithmen des maschinellen Lernens können Sie auf der Grundlage neuer, ungesehener Daten genaue Vorhersagen treffen. Es ist wichtig, den Prozess regelmäßig zu iterieren und für die spezifischen Anforderungen eines Projekts zu verfeinern. Wenn Sie darüber mit KI/ML-Spezialisten besprechen möchten, können Sie uns gerne kontaktieren.

50 % schnellerer Testprozess bei Smart City-Anwendungen
Design, Entwicklung, DevOps oder Cloud - welches Team brauchen Sie, um die Arbeit an Ihren Projekten zu beschleunigen? Chatten Sie mit unseren Beratungspartnern, um herauszufinden, ob wir gut zusammenpassen.
Jakub Orczyk
Vorstandsmitglied /Verkaufsdirektor
Buchen Sie eine kostenlose Beratung